LLM-grounded Video Diffusion Models
TL;DR: Text Prompt -> LLM as a front end -> Intermediate Representation (such a an dynamic scene layout) -> Video Diffusion Models -> Video.
LLM-grounded Video Diffusion Models (LVD)
Our LLM-grounded Video Diffusion Models (LVD) improves text-to-video generation by using a large language model to generate dynamic scene layouts from text and then guiding video diffusion models with these layouts, achieving realistic video generation that align with complex input prompts.

Motivation
While the state-of-the-art open-source text-to-video models still cannot perform simple things such as faithfully depicting object dynamics according to the text prompt, LLM-grounded Video Diffusion Models (LVD) enables text-to-video diffusion models to generate videos that are much more aligned with complex input text prompts.
Method
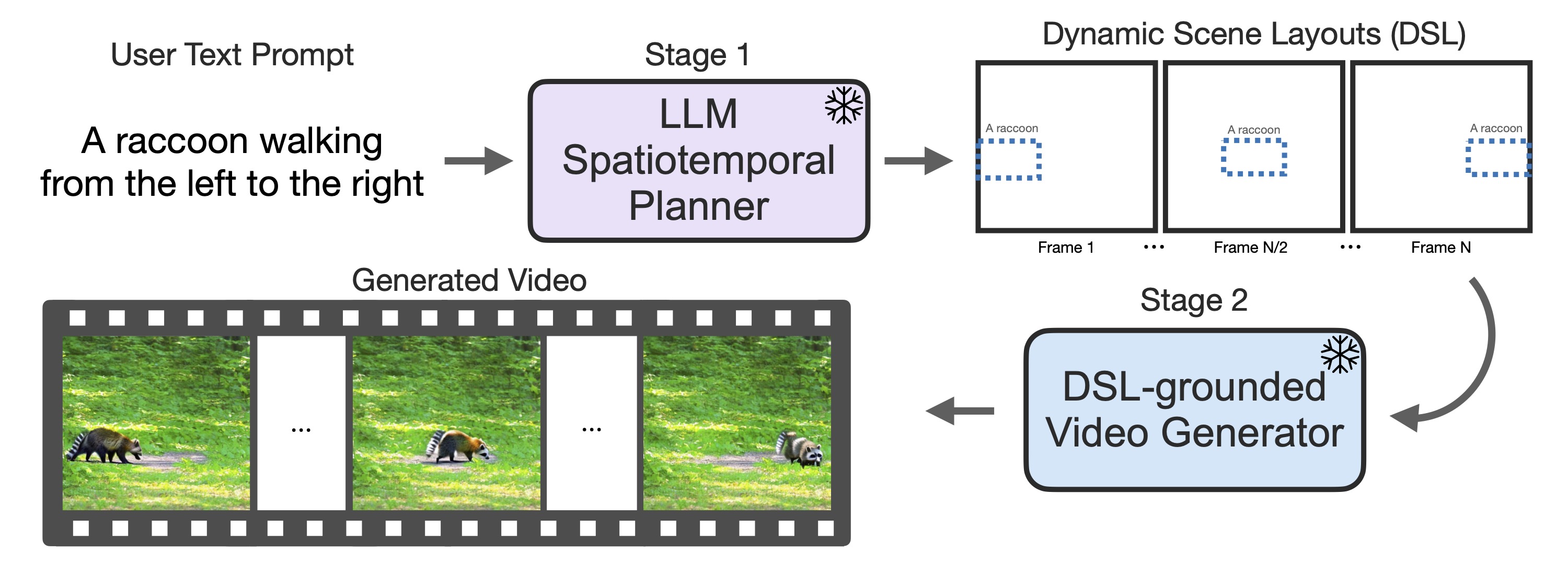
Our method LVD improves text-to-video diffusion models by turning the text-to-video generation into a two-stage pipeline. In stage 1, we introduce an LLM as the spatiotemporal planner that creates plans for video generation in the form of a dynamic scene layout (DSL). A DSL includes objects bounding boxes that are linked across the frames. In stage 2, we condition the video generation on the text and the DSL with our DSL-grounded video generator. Both stages are training-free: LLMs and diffusion models are used off-the-shelf without updating the parameters.
Investigation: can LLM generate spatiotemporal dynamics?
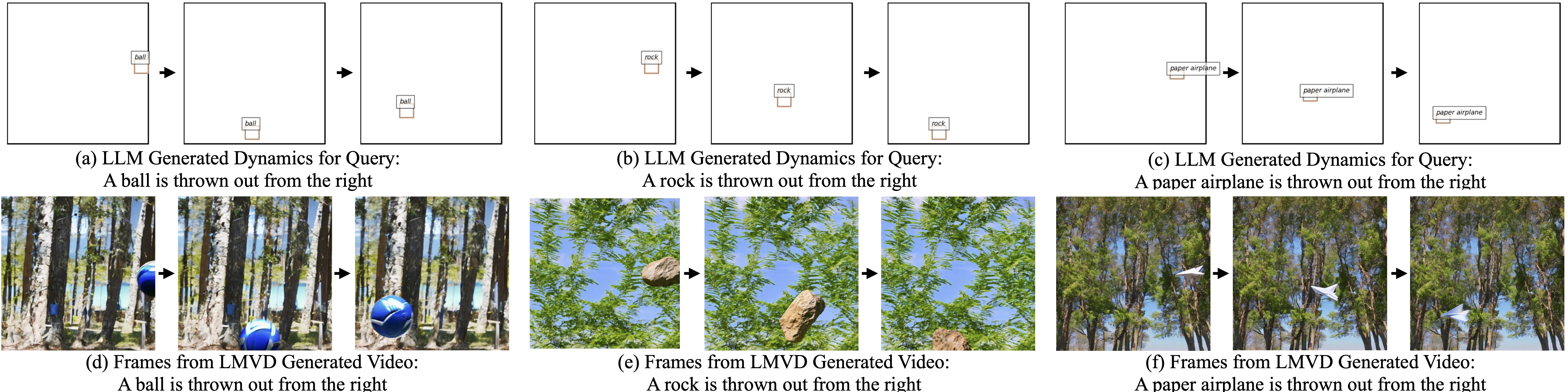
With only three fixed in-context examples that demonstrate three key properties, LLMs can generate realistic dynamic scene layouts (DSLs) and even consider other object/world properties that are not mentioned in the prompt or examples.
Three in-context examples that we use:

LLM generates dynamic scene layouts, taking the world properties (e.g., gravity, elasticity, air friction) into account:
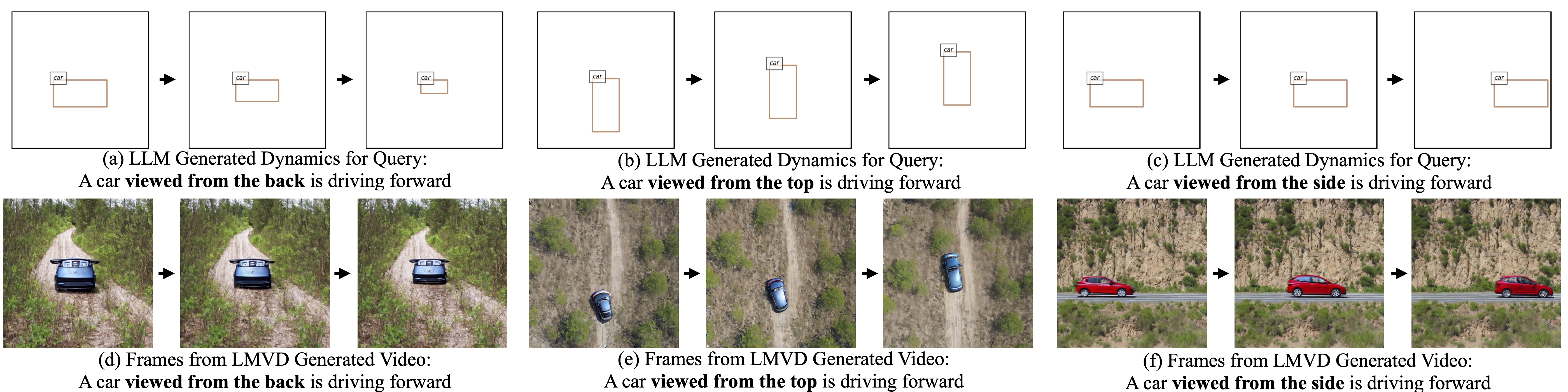
LLM generates dynamic scene layouts, taking the camera properties (e.g., perspective projection) into account:
Generating Videos from Dynamic Scene Layouts
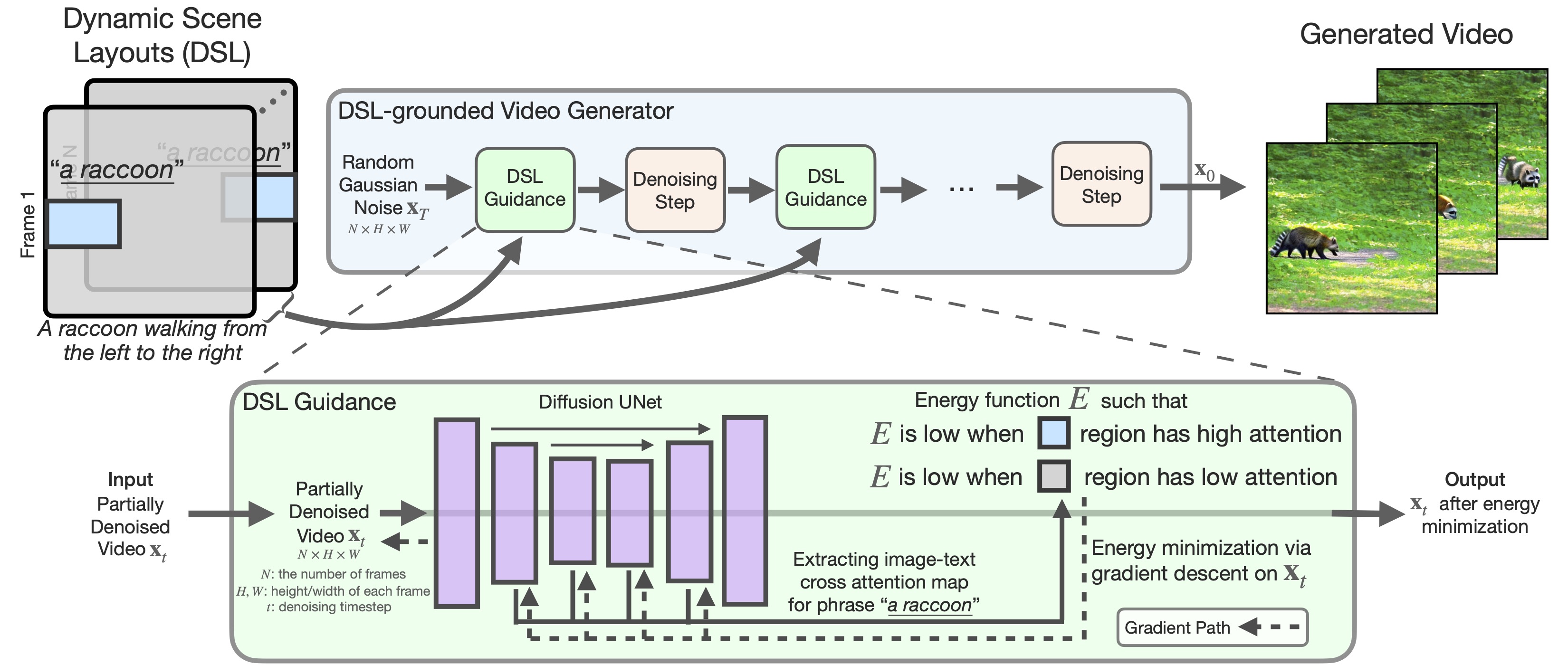
Our DSL-grounded video generator generates videos from a DSL using existing text-to-video diffusion models augmented with appropriate DSL guidance. In this stage, our method alternates between DSL guidance steps and denoising steps.
Visualizations
We propose a benchmark with five tasks. Without specifically aiming for each task, LVD performs much better compared to the base model, even though it does not change any diffusion model param.

Citation
If you use this work or find it helpful, please consider citing:
@article{lian2023llmgroundedvideo,
title={LLM-grounded Video Diffusion Models},
author={Lian, Long and Shi, Baifeng and Yala, Adam and Darrell, Trevor and Li, Boyi},
journal={arXiv preprint arXiv:2309.17444},
year={2023}
}
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}